# Template-Based Named Entity Recognition Using BART
# 前言
这是一篇发表于 2021 年 ACL findings 的论文,主要的方法是通过构造提示模版来解决 NER 问题,使用的 BART 这样的 Encoder 和 Decoder 结构。https://aclanthology.org/2021.findings-acl.161/
# 日期
2021 年
# 作者
Leyang Cui, Yu Wu, Jian Liu, Sen Yang, Yue Zhang
浙江大学
微软研究院
西湖大学
# 摘要
人们对进行小样本命名实体识别(NER)的研究表现出了兴趣,小样本命名实体中低资源目标领域与资源丰富的源领域具有不同的标签集。现有的方法使用基于相似度的度量。然而,它们无法充分利用 NER 模型参数中的知识传递。为了解决这个问题,我们提出了一种基于模板的 NER 方法,将 NER 视为一种语言模型排名问题并采用序列到序列的框架,其中原始句子和由候选命名实体跨度填充的模板分别被视为源序列和目标序列。在推断阶段,模型需要根据相应的模板分数对每个候选跨度进行分类。我们的实验证明,所提出的方法在 CoNLL03(资源丰富数据集上)上达到了 92.55%的 F1 得分,并且在 MIT 电影、MIT 餐厅和 ATIS(低资源任务)上明显优于微调 BERT,分别提高了 10.88%、15.34%和 11.73%的 F1 得分。
# 方法描述
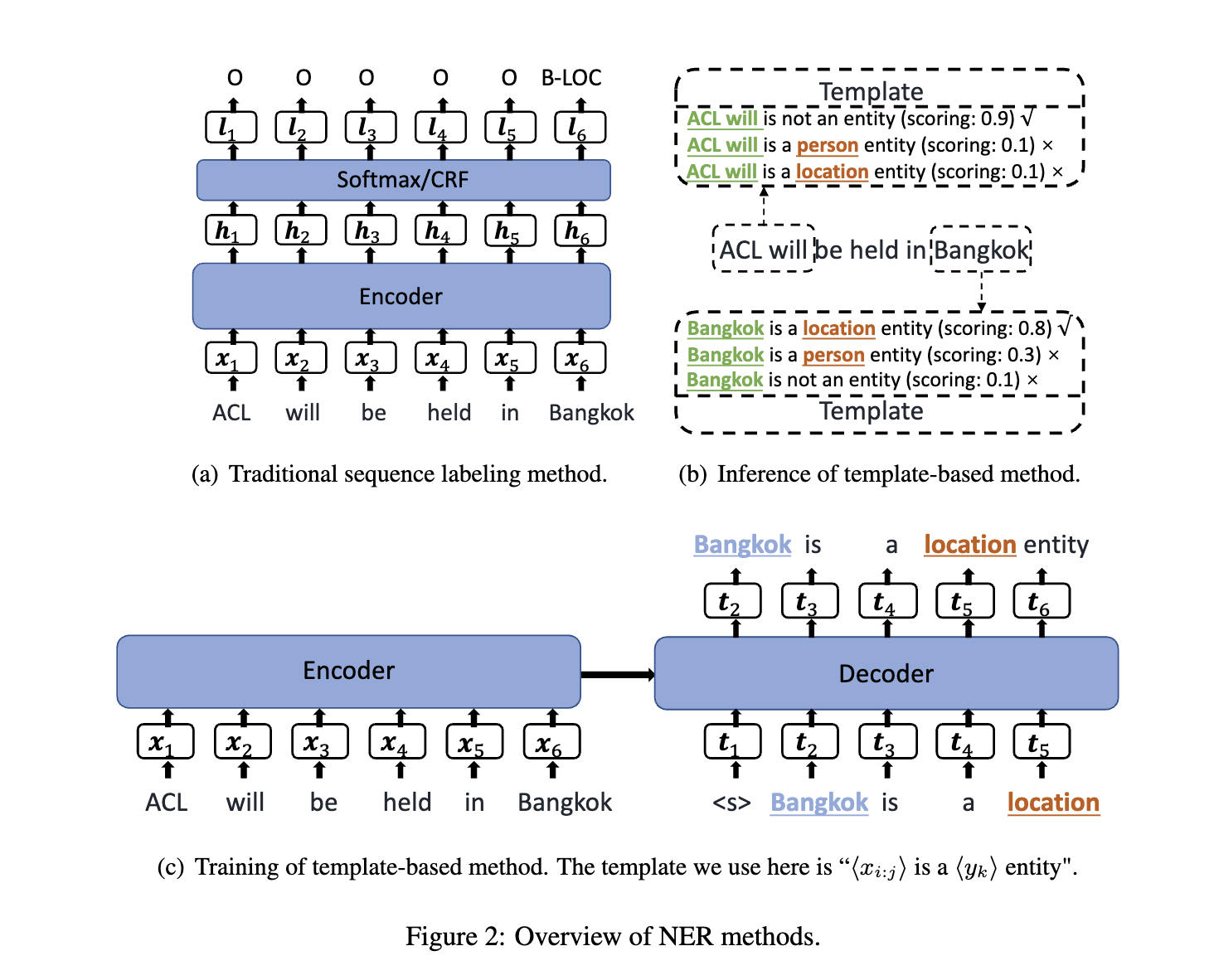
本文主要采用序列到序列的框架,输入序列 X、模版序列 T,根据单词和实体构造模版并分别对其进行评分。
模版的创建
模版采用手动构造的方式,主要包括两个插槽,其中一个是
candidate_span,另外一个插槽是entity_type。对于 NER 分类中的标签,都采用一个自然的单词来替代它,例如 LOC 的单词为 location。- 对于有标签的模版形式:<candidate_span> is a location entity。
- 对于无标签的模版形式:<candidate_span> is not a entity.
这样可以获取到一系列模版,包括多个正样本和一个负样本。
模版的表示: is a 以及 is not a entity.
推理阶段
由于第一个插槽是跨度,因此需要枚举所有的跨度来构造模版。(由于效率考虑,本文限制 gram 的长度最大为 8,因此,每一句话最多只有 8n 个的模版。
接着再通过生成模型对每个模版评分,其公式为:
通过这个公式得到每个标签的评分,评分最高的就为该实体的类型(或者是非实体)。由于本文的数据集不包含嵌套实体,因此,如果多个重叠的实体,则只保留最高的评分的实体。
训练阶段:
使用真实标签来构造相应的模版,这些模版作为正样本。除此之外,本文还从训练集中随机抽取了一些非实体的负样本。负样本的比例是正样本的 1.5 倍。
给定样本对(X,T),将 X 输入到 BART 的编码器中来获取原始输入 X 的隐藏状态:
然后解码预测出 T,其中每一步的隐藏状态为:
而第 c 步预测的单词概率为:
其中全连接是将 h 维度映射到 BART 的词数量高纬度来获取每个 vocab 的概率。
因此损失函数定义为:
# 迁移学习
由于使用了自然的单词作为标签,因此本文的方法可以传播知识。
# 实验
数据集
采用 CONLL2003(富资源)以及 MIT Movie Review(2013)、MIT Restaurant Review (2016)、ATIS(2016)作为跨领域的数据集。
实验结果
![image-20230919102200551]()
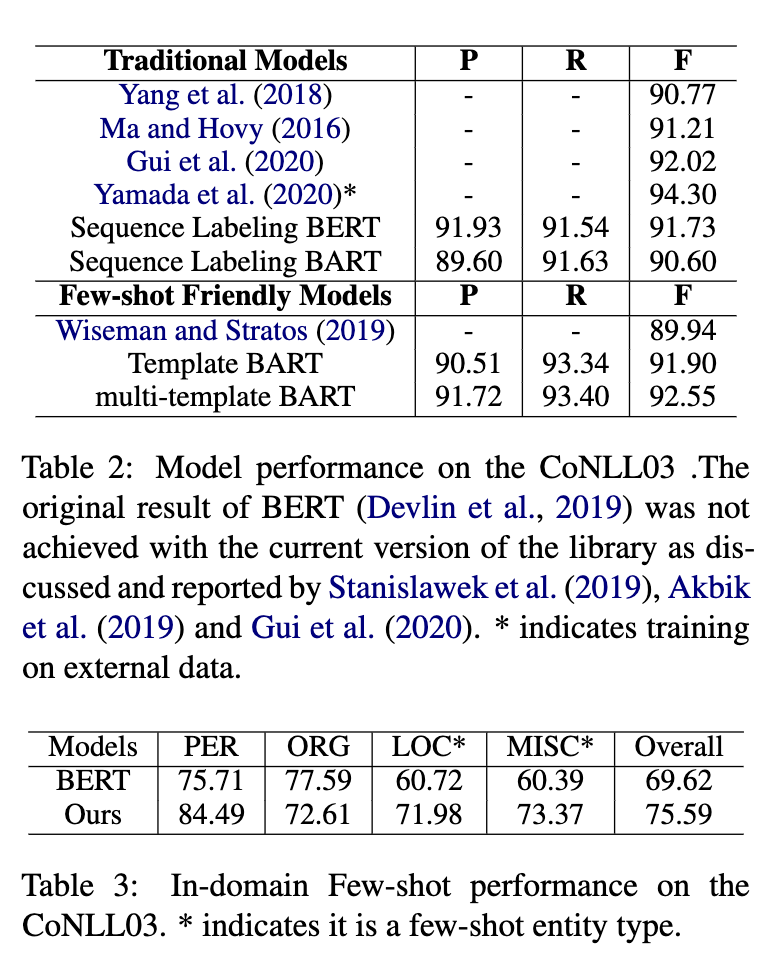
其中表 2 是在 CONLL2013 做标准的 NER 训练和评估。基线模型 BERT 的 F1 值为 91.73,而本文的模型最佳为 92.55。
表 3 为领域内小样本实验,训练集和测试集均来自于 CONLL2003,对于其中的四个类,PER 和 ORG 为富资源类型,而 LOC 和 MISC 为低资源类型。在训练中下采样获取了 3925 的 ORG、1423 的 MISRC、50 的 LOC、50 的 PER 作为训练集。从表 3 中可以看出针对 * 标注的小样本类型,TemplateNER 模型明显高于基准线的 BERT 模型。
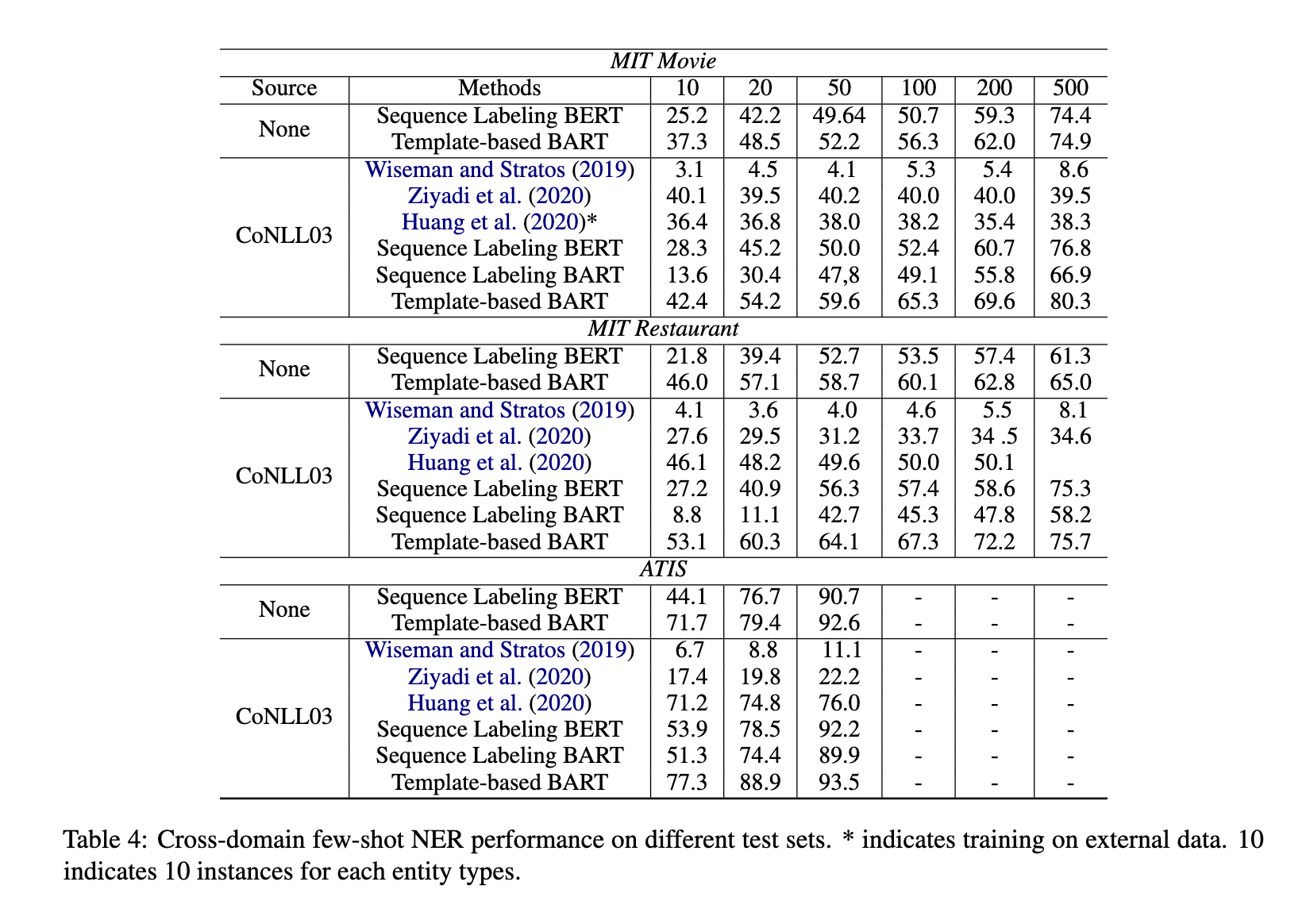
表 4 则是跨领域小样本测试,分为两种一种是在 CONLL2003 进行微调 、另外一种不做源领域训练。而在目标领域中仅仅按照上表抽取少量数量进行训练。
# 总结
这是 PromptNER 的前置文章,PromptNER 实验部分参考了这篇文章,实验设置一样。